PLATE-FROME III


2024-03-26 07:39:59
Découvrez AnyGPT : le futur LLM multimodal de l’IA open source?
AnyGPT est un Large Language Model (LLM) multimodal innovant capable de comprendre et de générer du contenu à partir de différents types de données, notamment la parole, le texte, les images et la musique. Ce modèle est conçu pour s’adapter à différentes modalités sans modification significative de son architecture ou de ses méthodes d’apprentissage.
https://www.blog-nouvelles-tec....hnologies.fr/285570/
2024-03-22 23:22:43
The Natiometer: From the Art of Measuring Nations to Quantum Technology. | #sciences humaines et sociales #ia #mécanique quantique.
2024-01-21 17:32:57
Fondée en 2022, #perplexity cherche à s'imposer dans le domaine de la recherche sur Internet en utilisant un chatbot comme interface #llm. Une proposition de valeur similaire à ce qu'offrent #google avec #bard et #microsoft avec #bingcopilot. L'utilisateur pose des questions en langage naturel et se voit retourner des résumés qui citent leurs sources. Il peut ensuite approfondir avec d'autres questions si nécessaire. La start-up a levé plus de 100 millions de dollars à date et aurait 10 millions d'utilisateurs actifs mensuels.
https://www.usine-digitale.fr/....article/perplexity-a

Perplexity AI lève 70 millions de dollars pour concurrencer Google avec son chatbot de recherche
2024-01-20 10:57:21
Dans le cadre du concours La preuve par l'image 2016 organisé par l’Association francophone pour le savoir – Acfas, l'animateur de Découverte, Charles Tisseyre, s'entretient avec Chérif Matta, de l’Université Mount Saint Vincent, autour de son image Les liaisons ingénieuses.
2024-01-15 13:47:42
Agence IA Générative .
https://www.agence-ia-generati....ve.com/
https://www
2023-11-15 15:57:18
Dans ce que beaucoup qualifient de
découverte révolutionnaire, une étude scientifique a trouvé des
structures multidimensionnelles à l’intérieur du cerveau humain.
https://aphadolie.com/2017/12/....10/cerveau-humain-mu

2023-11-12 19:01:43
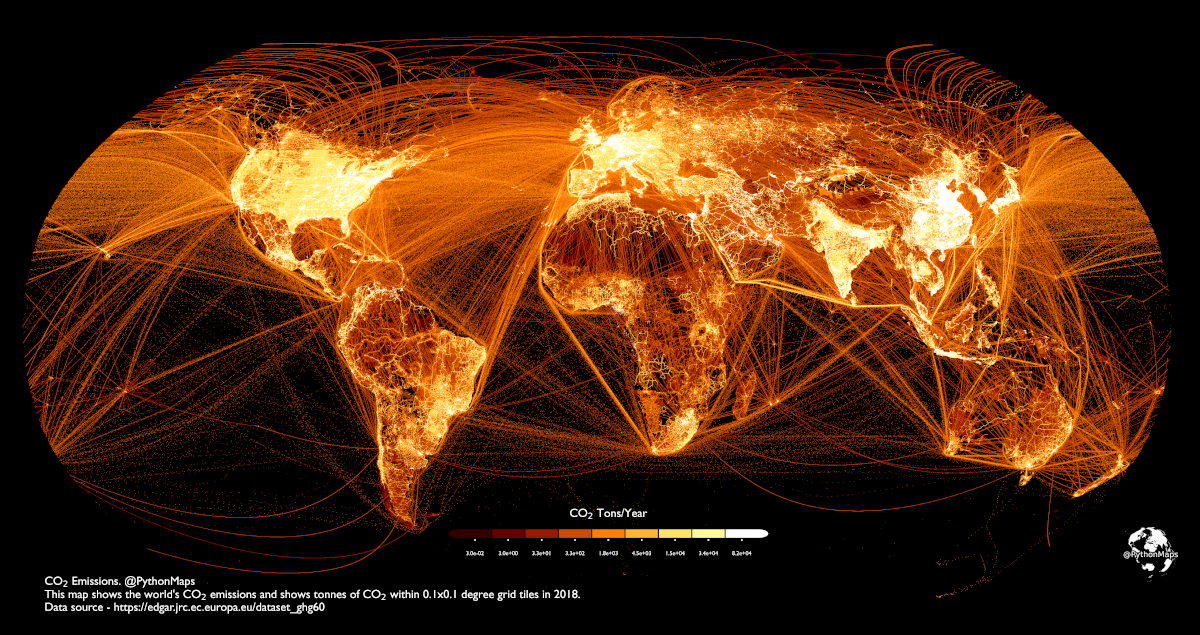
Où est émis le Co2 sur Terre?
Cette carte intense de Visual Capitalist est éloquente https://buff.ly/3AYqdaB
Nous
sommes peut-être au point culminant de l'âge thermo-industriel. La
population mondiale humaine a émis 36,8 milliards de tonnes de dioxyde
de carbone (CO₂) en 2022.
Cette visualisation d'Adam Symington
cartographie les émissions de carbone dans le monde, en utilisant les
données de 2018 de la Commission européenne qui suivent les tonnes de
CO₂ par grille de 0,1 degré (environ 11 kilomètres carrés).
Cette
carte spectaculaire nous permet de voir non seulement les centres de
population et de production industrielle, mais aussi les trajectoires de
vol, les voies de navigation et les zones de forte intensité carbone.
Vous pouvez examiner de plus près chaque continent sur l'article, ce sont les plus éclairées sur la carte.
Découvrir le détail : https://www.visualcapitalist.c....om/cp/mapped-carbon-
2023-11-09 19:25:18
Numalis lève 5 millions d’euros pour ses solutions de validation des algorithmes d'IA par méthode formelle
La start-up tricolore Numalis a finalisé un tour de table de 5 millions d’euros pour développer et déployer ses solutions de validation d’algorithmes d’IA par méthode formelle, qui montrent un intérêt particulier dans des secteurs critiques comme la défense ou la santé.
https://www.usine-digitale.fr/....article/numalis-leve

2023-11-08 22:20:56
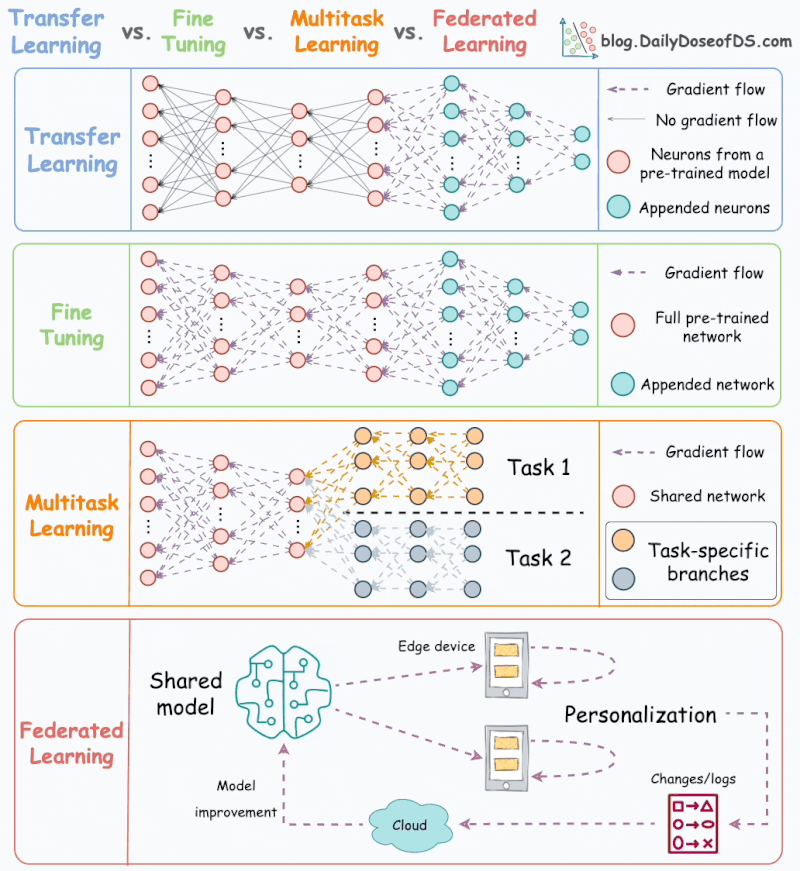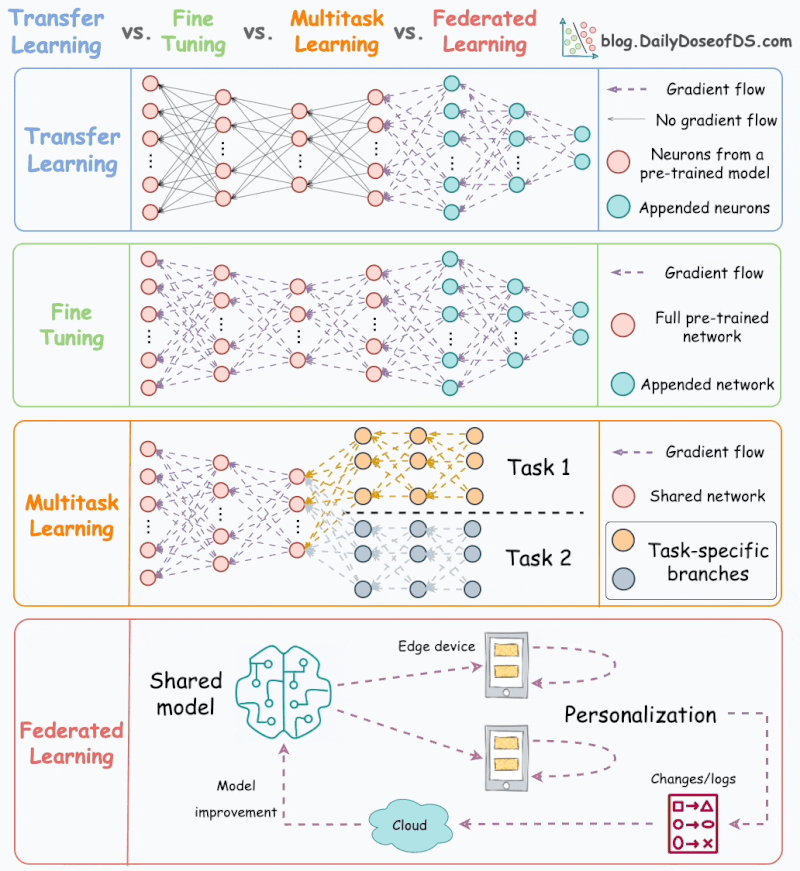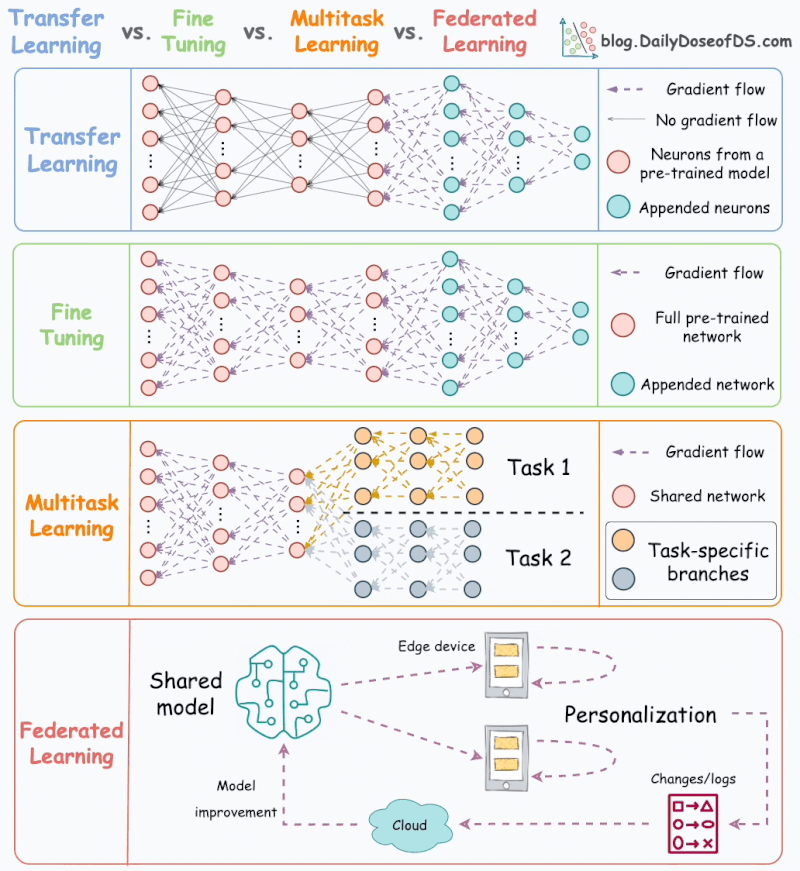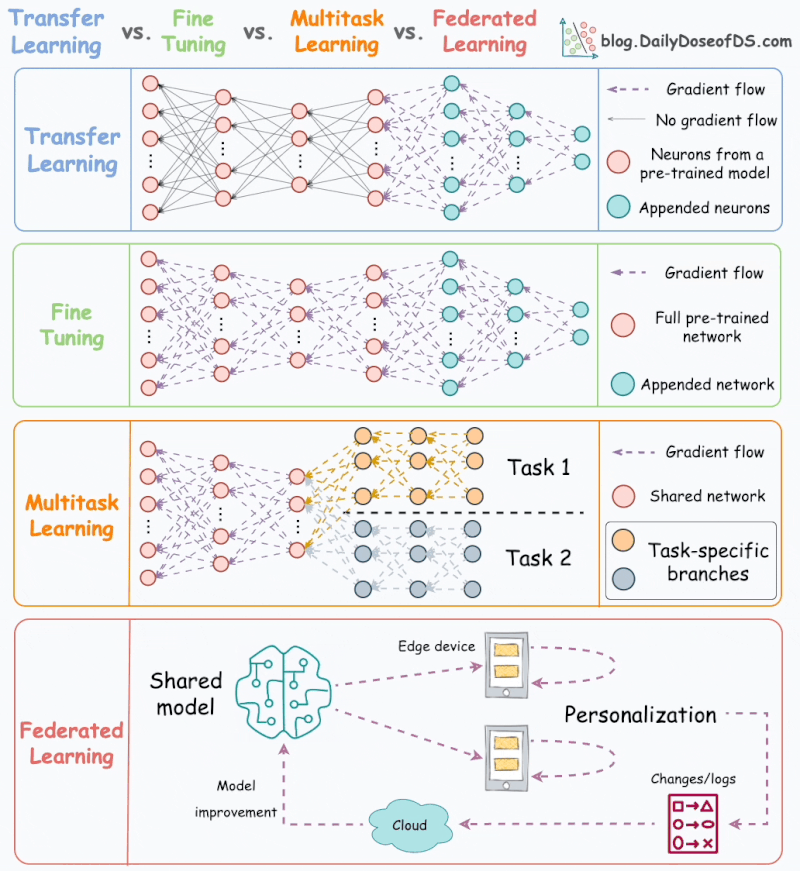
Apprentissage par transfert vs. Mise au point vs. Apprentissage multitâche vs. Apprentissage fédéré.
.
.
La plupart des modèles ML sont entraînés indépendamment sans aucune interaction avec d’autres modèles.
Mais
le ML dans le monde réel utilise de nombreuses techniques
d’apprentissage puissantes qui reposent sur des interactions de modèles.
L’animation suivante résume quatre de ces méthodologies de formation bien adoptées et incontournables :
--
👉 Vous trouverez une explication plus vivante avec des visuels ici : https://bit.ly/ml-lrng.
--
1) Apprentissage par transfert
Utile dans les cas suivants :
- La tâche d’intérêt contient moins de données.
- Mais une tâche connexe dispose de données abondantes.
Voici comment cela fonctionne :
- Entraînez un modèle de réseau de neurones (modèle de base) sur la tâche associée.
- Remplacez les derniers calques du modèle de base par de nouveaux calques.
- Entraînez le réseau sur la tâche qui vous intéresse, mais ne mettez pas à jour les pondérations des couches non remplacées.
L’entraînement sur une tâche connexe permet d’abord au modèle de capturer les modèles de base de la tâche d’intérêt.
Ensuite, il peut adapter les dernières couches pour capturer le comportement spécifique à la tâche.
2) Mise au point
Mettez à jour les pondérations de certaines ou de toutes les couches du modèle pré-entraîné pour l’adapter à la nouvelle tâche.
L’idée
peut sembler similaire à celle de l’apprentissage par transfert. Mais
ici, l’ensemble du modèle pré-entraîné est généralement ajusté aux
nouvelles données.
3) Apprentissage multitâche (MTL)
Un modèle est entraîné à effectuer plusieurs tâches connexes simultanément.
Du point de vue de l’architecture, le modèle présente les caractéristiques suivantes :
- Un réseau partagé
- Et des branches spécifiques à une tâche
La raison d’être est de partager les connaissances entre les tâches afin d’améliorer la généralisation.
En fait, nous pouvons également économiser de la puissance de calcul avec MTL :
- Imaginez entraîner 2 modèles indépendants sur des tâches connexes.
- Maintenant, comparez-le à un réseau avec des couches partagées, puis des branches spécifiques à une tâche.
L’option 2 se traduira généralement par :
- Meilleure généralisation sur l’ensemble des tâches.
- Moins de mémoire pour stocker les poids des modèles.
- Moins d’utilisation des ressources pendant la formation.
4) Apprentissage fédéré
Il
s’agit d’une approche décentralisée de l’apprentissage automatique.
Ici, les données d’entraînement restent sur l’appareil de l’utilisateur.
Donc,
d’une certaine manière, c’est comme envoyer le modèle aux données au
lieu des données au modèle. Pour préserver la confidentialité, seules
les mises à jour des modèles sont collectées à partir des appareils et
envoyées au serveur.
Le clavier de notre smartphone en est un excellent exemple.
Il utilise FL pour apprendre les modèles de frappe. Cela se produit sans transmettre les frappes sensibles à un serveur central.
Remarque : Ici, le modèle est entraîné sur de petits appareils. Ainsi, il DOIT être léger mais utile.
Les
techniques de compression de modèle sont répandues dans de tels cas.
J’ai mis en lien un guide détaillé dans les commentaires.
--
👉
Obtenez un PDF gratuit sur la science des données (550+ pages) avec
320+ articles en vous inscrivant à ma newsletter quotidienne dès
aujourd’hui : https://bit.ly/DailyDS.
--
👉 À vous de jouer : quelles sont les autres méthodologies de formation ML que j’ai manquées ici ?
2023-11-07 21:04:53
Les lois scientifiques.

2023-11-03 10:54:10
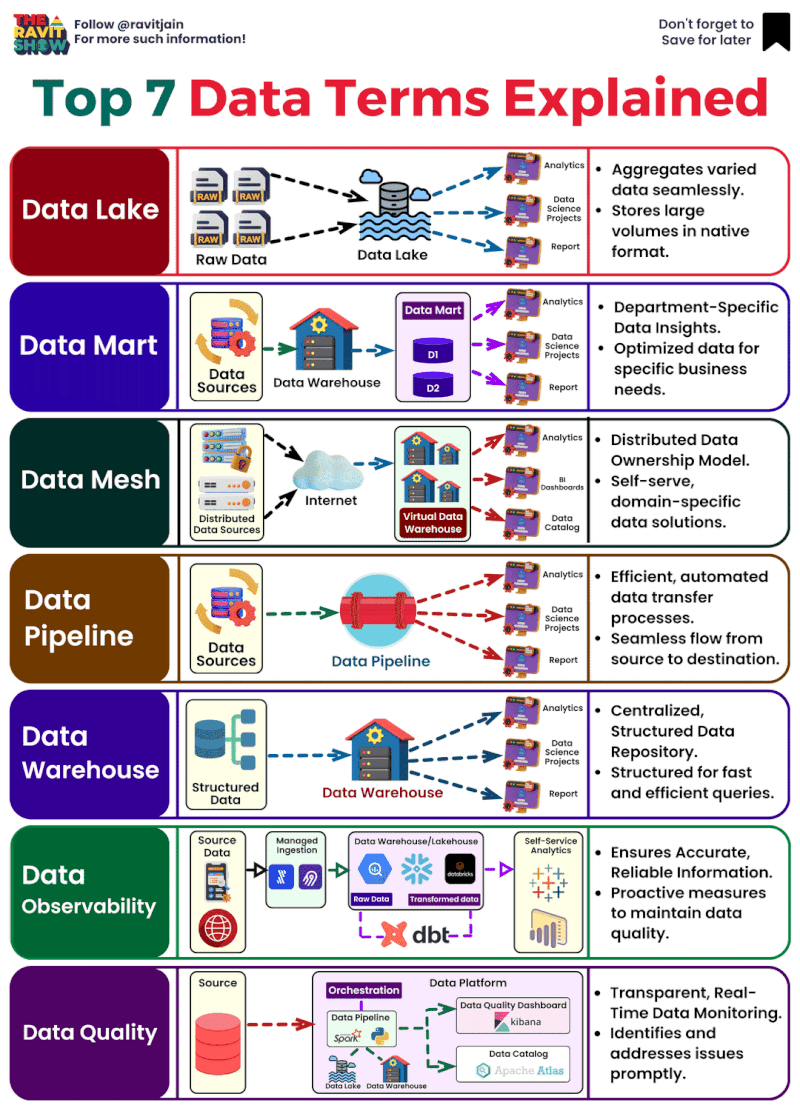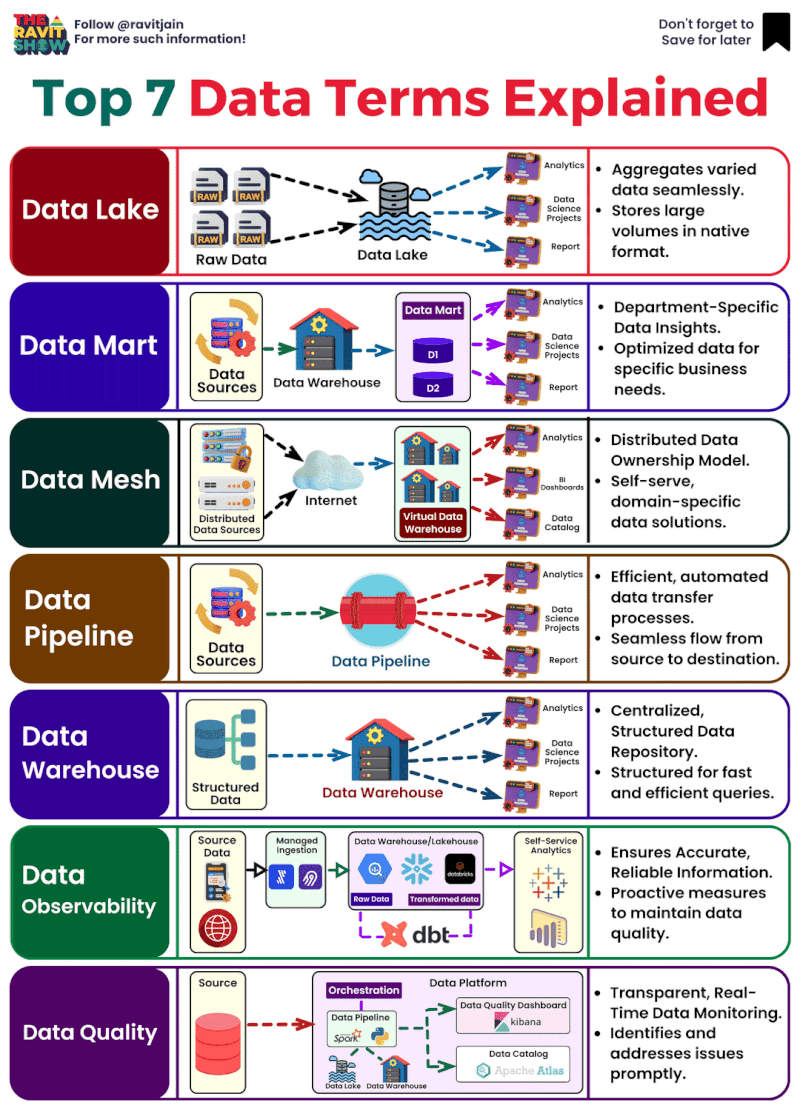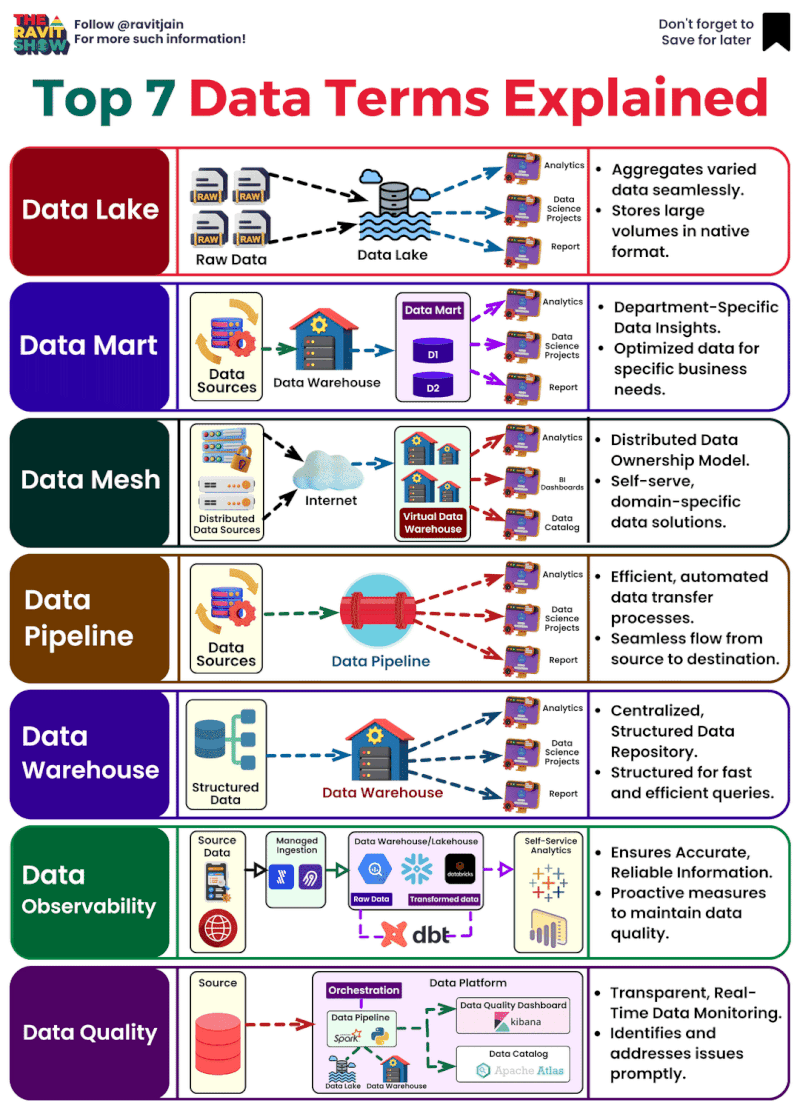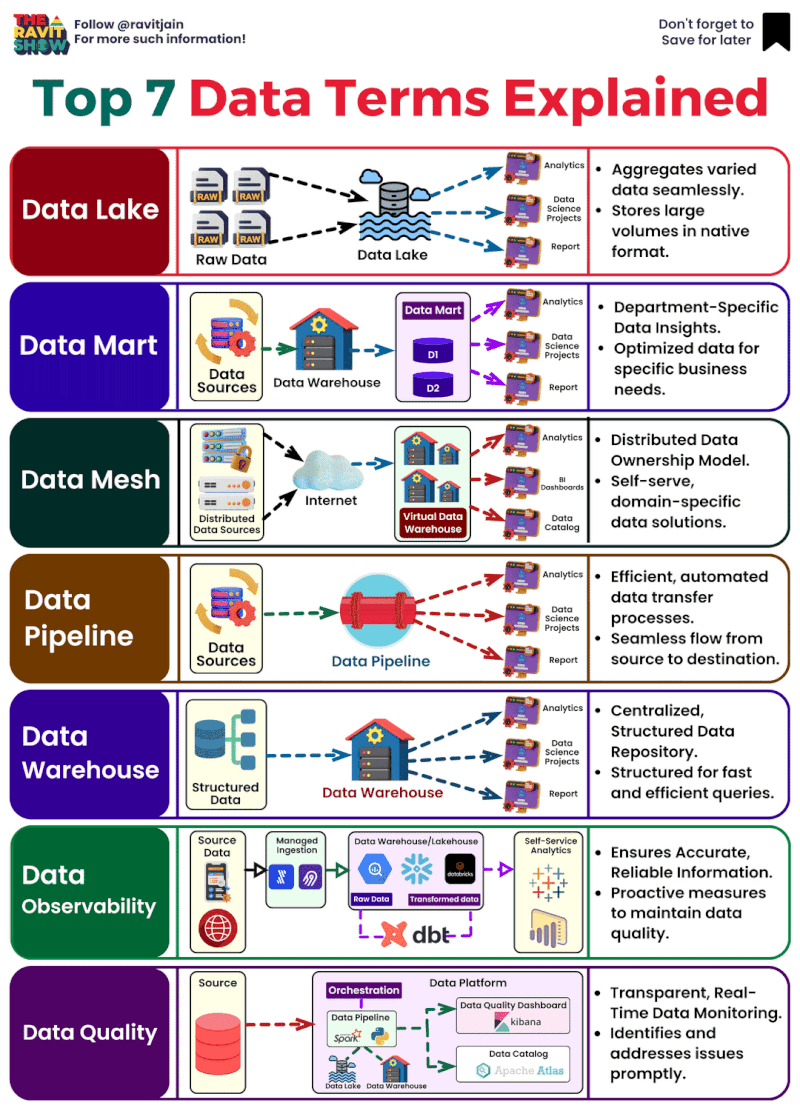
**Décodage de l’univers des données : les termes clés que tout professionnel devrait connaître**
Dans
le cosmos des données, il est essentiel de comprendre leurs différentes
facettes pour libérer leur puissance. Voici un aperçu des termes
essentiels qui façonnent nos récits axés sur les données. 🌌
🌊 **Data Lake
** : Un vaste réservoir de données brutes et non structurées. C’est le
point de départ, riche en possibilités, qui n’attend que d’être exploré.
Considérez-le comme la soupe primordiale d’où émergent toutes les
informations basées sur les données.
🛒 **Datamart
** : Une « boutique » spécialisée au sein du « marché » plus large d’un
entrepôt de données, axée sur un domaine d’activité spécifique. C’est
là que les données deviennent personnelles, adaptées aux requêtes
spécifiques à un domaine.
🕸 **DATA mesh
** : Une approche où les données sont décentralisées, ce qui permet aux
équipes individuelles de s’approprier et de contrôler. Ce réseau maillé
garantit que la valeur des données est maximisée grâce à une intendance
collective.
🚀 **Data Pipelines
** : Le flux dynamique de données, se déplaçant et se transformant de
l’état brut à l’état prêt. C’est le parcours qui prépare les données à
l’action, en les rendant accessibles et significatives.
🏛 **Data Warehouse
** : L’archive structurée où les données sont stockées, organisées et
prêtes à être analysées. C’est la base qui prend en charge la prise de
décision basée sur les données, un référentiel conçu pour la vitesse et
l’évolutivité.
🔎 **Data Quality
** : L’élément vital d’une analyse fiable. L’exactitude, la cohérence
et l’exhaustivité définissent la fiabilité des données. Sans qualité, il
n’y a pas de clarté.
👀 **Observabilité des données** : La
fenêtre sur l’état des systèmes de données. Il s’agit de maintenir la
visibilité pour garantir la fiabilité et les performances, le héros en
coulisses s’assurant que tout se passe bien.
Ces termes ne sont
pas seulement du jargon, ce sont les éléments constitutifs d’un monde
centré sur les données, et les comprendre est votre première étape vers
la maîtrise. 🛠
2023-10-20 16:34:20
La
capitalisation d’un projet Data repose sur la stratégie mise en place,
la gouvernance des données définie et l’apport d’une compréhension des
activités en mode Data Centric avec la transformation digitale de
l’entreprise. Un partenaire de confiance sait accompagner sur ces étapes
clés, mais il convient surtout d’approfondir ces enjeux de manière
opérationnelle pour ainsi matérialiser le produit Data attendu.
https://www.groupeonepoint.com..../fr/expertises/data-

2023-10-20 16:02:38
Aujourd’hui, dans les projets Data, une tendance actuelle reste l’expérimentation. Avoir la capacité d’explorer des cas d’usage et d’établir la valeur business
de ces derniers est devenu un enjeu majeur car les projets de
transformations globaux nécessitent très vite d’importants moyens
humains. La discipline qu’est l’intelligence artificielle n’échappe pas à
cette vérité contemporaine. En effet, cette science présente des
possibilités infinies mais réaliser un projet de Machine Learning
de bout en bout, de la détection du cas d’usage à l’industrialisation
et la maintenance du modèle en production, est un processus exigeant.
https://www.groupeonepoint.com..../fr/expertises/%cf%8

2023-10-19 14:33:03
Data & IA
Les économistes parlent
de General Purpose Technology. Au même titre que l’électricité ou
l’automobile. L’intelligence artificielle doit pouvoir se mettre au
service d’un monde en profondes mutations pour en relever les défis
économiques, sociétaux et environnementaux.
https://www.groupeonepoint.com..../fr/nos-publications

2023-10-19 11:12:04
Un grand nombre d’entreprises se trouvent
aujourd’hui confrontées à des problématiques data. Beaucoup d’entre
elles sont prises au dépourvu devant la complexité apparente et
grandissante de ces enjeux. Les réflexions sur les nouveaux modèles
d’organisation ont fait émerger de nouvelles pratiques systémiques pour
permettre de limiter l’apparition de silos et d’adresser les différents
besoins dans leur globalité. Le Data Product Management est l’une de ces
pratiques.
https://www.groupeonepoint.com..../fr/nos-publications

2023-10-19 11:00:20
La transformation des organisations et des modèles d’affaire vers une
stratégie dite data-driven reste un programme difficile dont le succès
n’est pas garanti malgré, généralement, l’adhésion initiale par
consensus des parties prenantes.
https://www.groupeonepoint.com..../fr/nos-publications

2023-10-17 23:24:04
La course aux Data Products a débuté, mais il ne s’agit pas de
savoir combien de produits de données vous pouvez créer ou combien de
sources de données vous pouvez intégrer. Cet article se concentre sur
l’optimisation à travers quatre leviers clés : le coût, la performance, le risque et l’expérience utilisateur. Ces leviers doivent être équilibrés en fonction de vos priorités et d’une bonne compréhension des compromis à faire.
https://www.groupeonepoint.com..../fr/nos-publications

2023-10-13 19:35:39
IA : Cette technique oubliée du 18e siècle rend le Deep Learning inutile.
https://www.lebigdata.fr/deep-learning-inutile

2023-10-12 16:11:38
“ Le renseignement pour la souveraineté ”
Lors de mon entretien avec Sivagami Casimir pour le magazine Archimag, nous avons parlé :
▪️ De renseignement au profit des entreprises ;
▪️ Du nectar informationnel ;
▪️ De souveraineté économique.
https://www.prisme-intelligence.com/

2023-10-11 01:08:05
En 1969, au Sel de la semaine, Thérèse Gouin-Décarie s'entretient pendant près d'une heure avec Jean Piaget. Après avoir parlé de ses premiers travaux, l'épistémologiste explique comment ses théories et expériences l'ont amené à mieux comprendre les étapes du développement de l'intelligence. Piaget est considéré comme l'un des scientifiques les plus importants du 20e siècle, comme celui a révolutionné les conceptions de la pensée de l'enfant. À la fois psychologue et biologiste, il s'est spécialisé en épistémologie, une science qui se penche sur la construction des connaissances. L'intervieweuse, Thérèse Gouin-Décarie, a enseigné à l'Université de Montréal de 1951 à 1991. Sa thèse de doctorat, publiée en 1962 sous le titre Intelligence et Affectivité chez le jeune enfant, fut le premier ouvrage scientifique à allier les théories de Jean Piaget et les thèses de Freud sur le développement de l'enfant.
Source : Le sel de la semaine, 9 octobre 1969.
2023-09-29 20:21:22
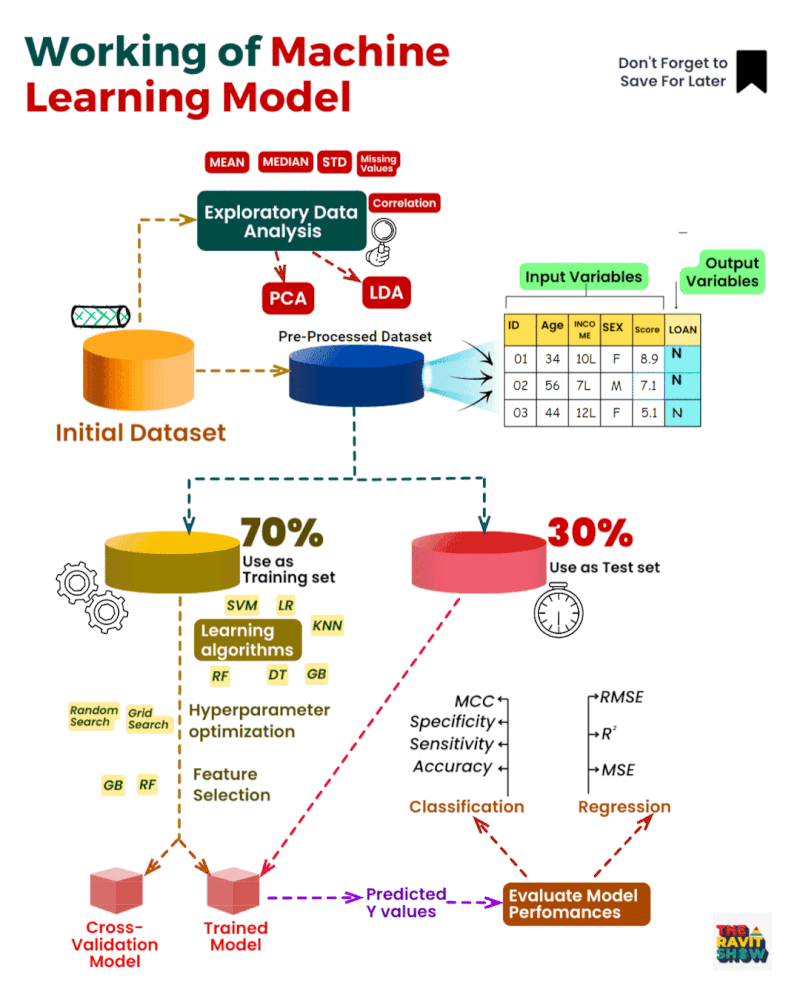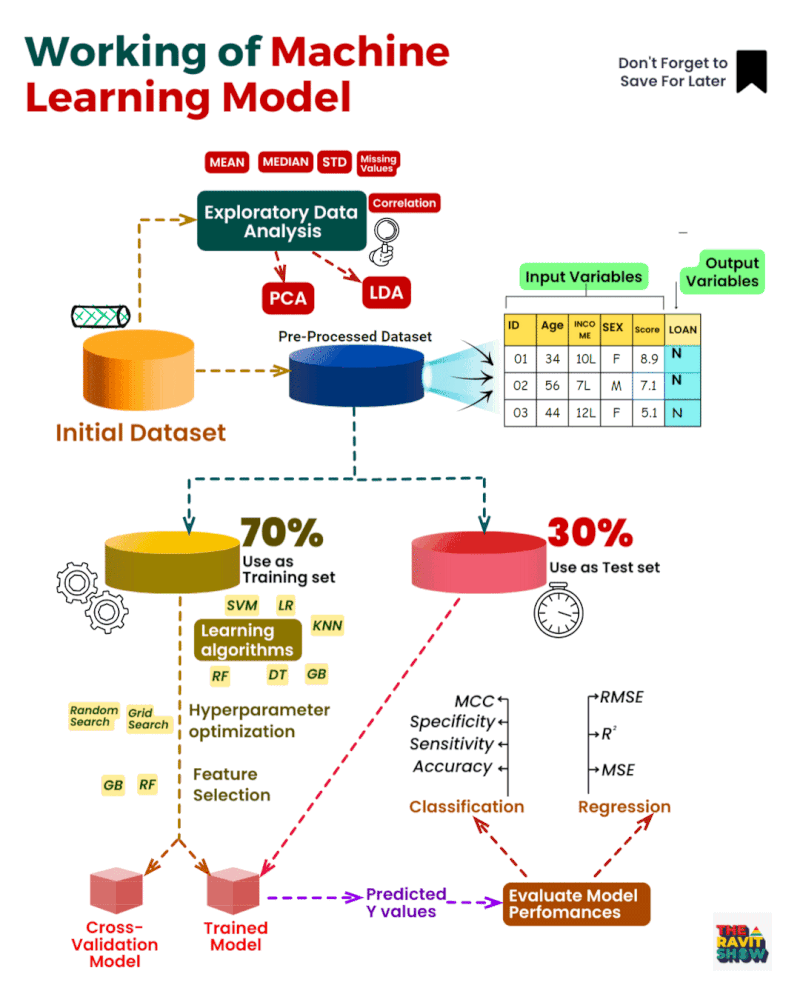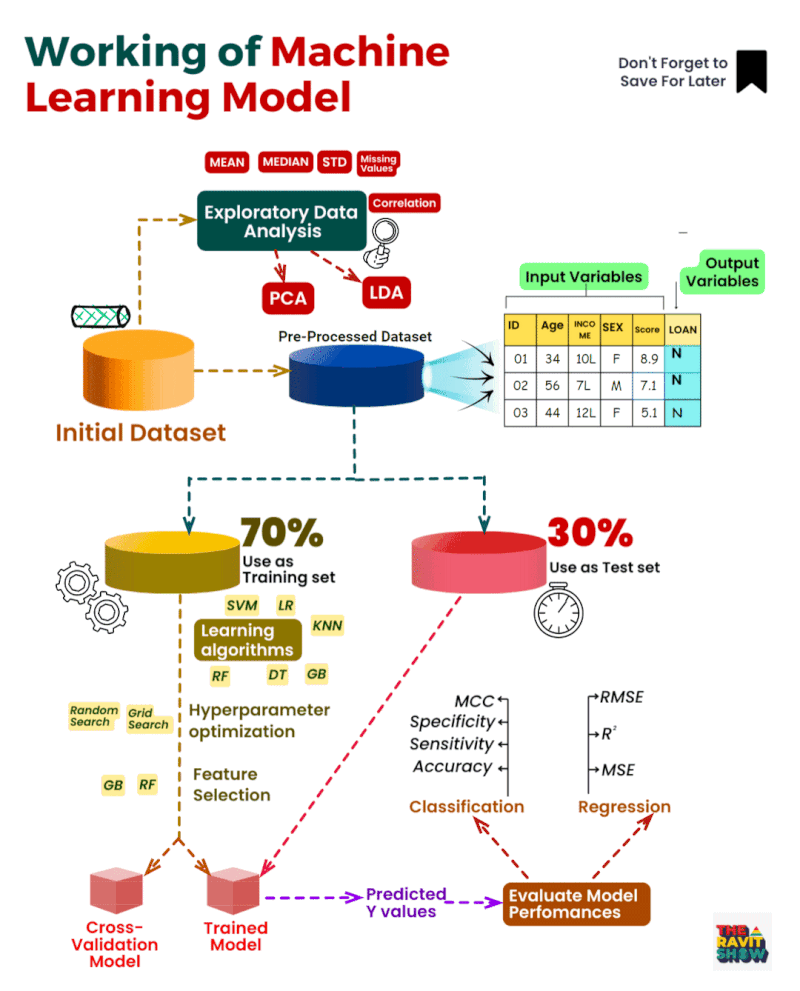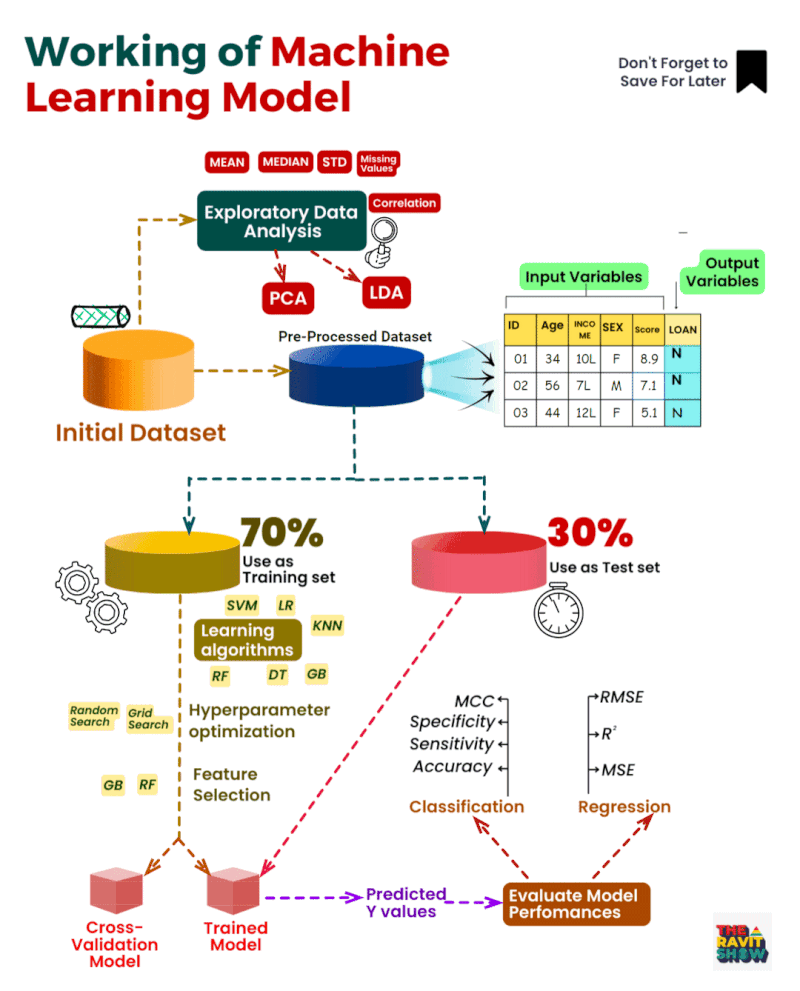
Comprendre le processus d’apprentissage automatique :
Acquisition
de données : Processus d’approvisionnement et de collecte d’ensembles
de données pertinents pour l’apprentissage automatique ou l’analyse.
Analyse
exploratoire des données (EDA) : Analyse complète pour visualiser les
tendances, détecter les anomalies et tirer des enseignements des
données.
Nettoyage des données :
Correction des erreurs et correction des valeurs manquantes pour assurer
la cohérence des ensembles de données.
Prétraitement
des données : Des techniques telles que l’ACP (analyse en composantes
principales) sont utilisées pour simplifier et normaliser les données.
Sélection
des caractéristiques : Identifier et mettre l’accent sur les variables
les plus percutantes de l’ensemble de données afin d’améliorer la
précision des prédictions.
Fractionnement
train-test : le jeu de données est divisé en un ensemble
d’apprentissage, utilisé pour instruire le modèle, et un ensemble de
tests, utilisé pour évaluer ses performances.
Formation
de modèle: Utilisation d’algorithmes tels que SVM, KNN, RF, entre
autres, pour entraîner le système sur des modèles à partir des données.
Optimisation
des hyperparamètres : Ajustement des paramètres du modèle, à l’aide de
méthodes telles que la recherche de grille, pour des performances
optimales.
Validation croisée : évaluation des performances du modèle sur différents sous-ensembles de données pour vérifier sa robustesse.
Prédiction du modèle : Après l’entraînement, le modèle formule des prédictions basées sur l’ensemble de tests.
Mesures
de performance : la précision des prédictions du modèle est évaluée à
l’aide de mesures telles que la précision, RMSE, MSE et R².
Analyse de régression : Étude de la relation entre les variables indépendantes et dépendantes dans l’ensemble de données.
Évaluation du modèle : Une évaluation approfondie de l’exactitude du modèle avec des ajustements potentiels au besoin.
2023-08-25 17:34:44
De
nouveaux codes puissants correcteurs d'erreurs quantiques pourraient
aider à accélérer l'arrivée d'ordinateurs quantiques utiles.
https://www.quantamagazine.org..../new-codes-could-mak

2023-08-25 14:54:20
L’intelligence
artificielle permettrait de cartographier en un temps record toutes les
configurations moléculaires possibles, selon une étude. Un tel outil
permettrait d’accélérer le développement de nouveaux médicaments et de
matériaux ultraperformants.
https://trustmyscience.com/ia-....chercheurs-proposent

2023-08-19 22:25:35
La
mécanique quantique nous montre que la même expérience, répétée à
plusieurs reprises dans les mêmes conditions, peut donner des résultats
différents.
https://bigthink.com/13-8/quan....tum-superposition/#E
2023-08-19 01:04:04
Depuis
leur découverte dans les années 1830, les groupes sont devenus l'un des
objets les plus importants en mathématiques. La théorie de la
représentation aide les mathématiciens à convertir le monde parfois
mystérieux des groupes en un territoire bien traîné de l'algèbre
linéaire. (à partir de 2020)
https://www.quantamagazine.org..../the-useless-perspec

2023-08-17 16:08:22
Des
chercheurs ont développé une approche utilisant un « spin quantique
central » pour simplifier les calculs quantiques, permettant une
diminution des erreurs, une vitesse accrue ainsi qu'une meilleure
compatibilité avec divers algorithmes clés.
https://trustmyscience.com/inf....ormatique-quantique-
2023-08-15 18:57:19
Des
chercheurs ont développé une technique d'imagerie superrésolution,
baptisée « PINE », révélant des détails inédits sur la division
cellulaire.
https://trustmyscience.com/nou....velle-technique-imag
2023-08-14 00:04:41
Plus
tôt cet été, les étudiants de l'Université du Colorado, Boulder ont
découvert un problème avec la conjecture locale-mondiale, une prédiction
sur les emballages de cercle que de nombreux théoriciens des nombres
avaient considéré comme étant tout sauf prouvé.
https://www.quantamagazine.org..../two-students-unrave

2023-06-06 04:59:40

{kind=link}
2023-04-19 21:14:23
« Data Lakehouse » est une architecture de données moderne et ouverte qui combine la performance et l'optimisation d'un entrepôt de données avec la souplesse d'un lac de données. Mais maximiser la valeur exige des pratiques exemplaires.En savoir plus :
https://www.technologyreview.c....om/2023/03/17/106968
2023-04-13 20:50:57
🤖 Ils développent une nouvelle IA scientifique appelée IA Descartes, qui combine théorie et données pour accélérer les découvertes scientifiques.
AI-Descartes offre certains avantages par rapport aux autres systèmes, mais son trait le plus distinctif est sa capacité de raisonnement logique, ce qui est la différence de CHAT GPT, qui a des compétences logiques plus limitées.
Vous pouvez lire la nouvelle complète ici ➡
https://techxplore.com/news/20....23-04-ai-scientist-c

2023-04-13 19:37:24
Tour à tour présentée comme « la femme la plus puissante de l’IA » ou la « créatrice de ChatGPT » par la presse anglophone, Mira Murati est pourtant restée longtemps dans l’ombre de Sam Altman. Portrait de l'autre visage de l'entreprise qui cristallise aujourd'hui toutes les tensions... 👇
https://usbeketrica.com/fr/art....icle/mira-murati-la-

2023-04-09 01:02:18
ChatGPT va-t-il détruire le monde ? avec Laurent Alexandre.
Le fondateur de ChatGPT, Sam Altman, a déclaré : « L’Intelligence Artificielle va très probablement mener à la fin du monde, mais entretemps, il y aura de grandes entreprises. » La course à l’IA générative s’est soudain accélérée. Toutes les grandes sociétés de la tech déploient des efforts immenses pour mettre le plus rapidement possible à disposition des outils toujours plus puissants.
Quels sont les prochains développements attendus de la technologie ? Quels bouleversements vont être provoqués par le développement de l’IA générative ? Faut-il craindre un bouleversement du marché du travail ? Que signifierait un monde où chacun se réfèrerait à une même source ? Qui la contrôlera ?
Pour répondre à ces questions, Olivier Babeau a échangé avec Laurent Alexandre, chirurgien et expert en Intelligence Artificielle.
2023-04-08 05:10:23
Le magazine de l'Institut Paul Scherrer Numéro 2/2022
https://issuu.com/paul-scherre....r-institute/docs/523

2023-04-08 04:24:27
ChatGPT peut coder un malware à la place des pirates 😱
ChatGPT est une arme redoutable pour les hackers. Avec l’aide de l’IA, il est possible de coder un dangereux malware indétectable… sans écrire une seule ligne de code.
https://www.01net.com/actualit....es/ce-malware-indete

2023-04-07 09:56:17
Objectif Quantique, c’est une toute nouvelle émission de 01TV dédiée au monde du quantique en général. Présentée par Jérôme Colombain, elle déchiffre et analyse ce concept qui se décline à travers de nombreuses technologies, et des usages variés.
2023-04-07 05:55:53
Avez-vous déjà vu un ordinateur quantique ?
écrit par Edern Rio
Selon toute vraisemblance, l’ordinateur quantique sera la prochaine révolution de l’informatique. Vous avez sans-doute déjà lu des articles à ce sujet, y compris dans nos colonnes. Mais savez-vous à quoi ressemble un ordinateur quantique ?
https://opportunites-technos.c....om/avez-vous-deja-vu

2023-04-07 00:36:36
De l’Antiquité à nos jours, les moyens d’investigation sur le monde ont évolué pour aboutir à une démarche dont les fondements sont communs à toutes les sciences de la nature (physique, chimie, sciences de la vie et de la Terre). Découvrez dans cette animation-vidéo l'évolution de la démarche scientifique au fil du temps.
Une animation-vidéo co-réalisée avec L'Esprit Sorcier.
Pour en savoir plus sur la démarche scientifique, consultez notre fiche pédagogique : http://www.cea.fr/comprendre/Pages/ph...
2023-04-06 23:47:11
Google Translate n'est plus seul ! L'IA permet maintenant de traduire en quasi instantané... du code !
L'intelligence artificielle promet de remplacer de nombreux métiers en automatisant les tâches qui sont encore actuellement effectuées à la main. Et parmi celles-ci, il semble que la programmation informatique ait du souci à se faire.
https://www.clubic.com/technol....ogies-d-avenir/intel

2023-04-05 00:24:08
Comment rédiger de bons prompts pour l’IA ? Ces dernières semaines, on vous a parlé d’Intelligence Artificielle à toutes les sauces. Mais personne ne vous a dit comment l’exploiter efficacement pour générer des textes utilisables pour votre entreprise.
Alors, j’ai collecté plusieurs conseils actionnables pour vous aider à obtenir de bons résultats. Suivez le guide et consultez mes 3 bonnes
pratiques ci-dessous avant de vous lancer.
https://marketing-en-b2b.fr/pr....ompt-pour-intelligen

2023-04-03 22:41:06
Logiciels de machine learning
Un logiciel de machine learning peut extraire des informations à partir de données et créer des modèles logiques basés sur ces informations. Ces modèles peuvent ensuite être
appliqués par logiciel à l'automatisation future des processus.
https://www.capterra.fr/direct....ory/31103/machine-le

2023-04-03 22:41:06
Logiciels de machine learning
Un logiciel de machine learning peut extraire des informations à partir de données et créer des modèles logiques basés sur ces informations. Ces modèles peuvent ensuite être
appliqués par logiciel à l'automatisation future des processus.
https://www.capterra.fr/direct....ory/31103/machine-le
2023-04-03 22:31:55
Logiciels de simulation
Les ingénieurs recourent aux outils de
simulation pour imiter un phénomène réel avant de fabriquer le produit.
Les logiciels de simulations informatiques sont essentiellement des
programmes qui
permettent aux utilisateurs d'observer une opération par le biais d'une
simulation sans effectuer cette opération. Ils sont souvent utilisés
pour faire en sorte que le produit final soit aussi proche que possible
des spécifications de conception afin d’éviter tout coût supplémentaire.
Ce type de logiciel peut être utilisé pour la recherche, le testing ou
la formation. Il fournit des données critiques sur presque tout type de
projet avant la phase de prototypage.
Parcourez notre liste de produits pour trouver l’outil de simulation en
France qui répondra à vos attentes. Vous pouvez aussi sélectionner les
logiciels de simulation gratuits. Voir aussi : logiciel CAO pour
professionnels.
https://www.capterra.fr/direct....ory/30607/simulation

2023-03-31 18:35:10
Dans
cet épisode de Inside Israeli Innovation, Maayan Hoffman et Zachy
Hennessey fournissent une définition de l'intelligence artificielle et
explorent son impact sur notre vie quotidienne.
https://www.jpost.com/podcast/....inside-israeli-innov

2023-03-31 02:39:38
L'intelligence artificielle gagne en importance dans le processus de recherche et de développement de médicaments.
https://www.allnews.ch/partena....ires/content/cr%C3%A

2023-03-30 19:13:45
Une autre trouvaille et réalisation ! L'arbre de vie « étendu » crée les lignes de rapport d'or ( φ) du cube de Metatron, dont toute géométrie émerge. Les lignes φ Metatron (36° et 72°) sont fondamentales à l'hyperdimensionnel et à la perspective multidimensionnelle que l'on peut trouver et utiliser dans le cube de Metatron, (que DaVinci aurait beaucoup travaillé avec cette géométrie particulièrement). La fusion du Pentagone et de l'Hexagone ; la convergence du rationnel et de l'irrationnel. L'art rencontre la science ; le cerveau gauche et le cerveau droit. ACCEPTER la polarité, c'est la TRANSCENDRE. Le Pentagone apporte l'élément émotionnel et créatif au mariage des 5 et des 6. La géométrie est si belle et incroyable...
workuvre d'art par RG.
https://robertedwardgrant.com/....the-extended-tree-of
2023-03-30 19:02:31
"Nous, scientifiques, nous sommes en train de paniquer".
La biologiste Caroline Nieberding.
https://www.lalibre.be/planete..../environnement/2023/

2023-03-30 17:43:33
Les processus quantiques pourraient aider à expliquer l'énorme pouvoir du cerveau et sa capacité à générer de la conscience.
https://www.freethink.com/scie....nce/consciousness-qu